隨著 Google 新一輪 AI 廣告產品的發布,廣告投放的未來已經確定會越來越仰賴廣告巨頭的黑盒子演算法,廣告投手可以手動調整的槓桿會越來越少。
以前可能還可以靠受眾設定、版位拆分、出價策略、興趣包測試來拉開差距。但現在真正影響廣告系統學習品質的,已經不是你多會調後台設定,而是你能不能餵給系統足夠、正確、乾淨的轉換訊號。
就像 AI 發展的競爭趨勢一樣,科技巨頭們比起算法的演進更重視於電力跟晶片量能等基礎建設的競爭。我們作為數位廣告投手也應該更重視這塊資料基礎建設的競爭。

從 2017 年開始,Apple 推出 ITP(Intelligent Tracking Prevention,智慧防追蹤)成為了後 cookie 時代的濫觴,各大瀏覽器和作業系統都逐步跟進強化使用者隱私保護。第三方 Cookie、跨站追蹤、前端 JavaScript 追蹤,都不再像過去那麼穩定。更遑論全球約有 30% 至 35% 的網路使用者會在至少一台裝置上使用廣告攔截器。僅依賴前端追蹤的可靠性早已大不如前,但大多數網站依舊只使用 Pixel 和前端 GTM (Google Tag Manager) 在部屬追蹤。
這就是為什麼廣告轉換成本越來越高的根本原因。不是因為平台演算法越來越爛,而是你送給廣告系統的訊號,本來就已經破洞了。
Client-Side 追蹤的運作邏輯
傳統埋放 Facebook Pixel、Google Ads Tag 或各種第三方追蹤碼的方式,本質上都是 Client-Side Tracking。
簡單來說,就是把一段 JavaScript 腳本放在網頁裡,讓使用者的瀏覽器負責執行追蹤任務。
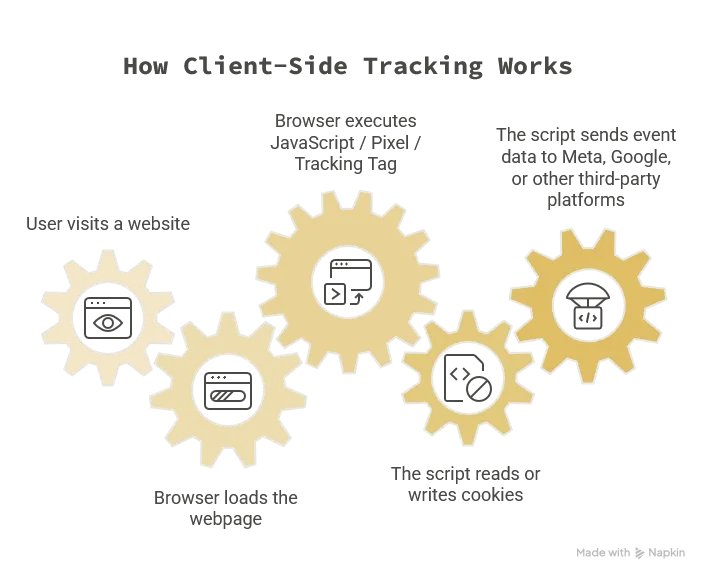
整個流程大概可以拆成三步:
- 載入: 使用者進入網站後,瀏覽器下載並執行第三方追蹤腳本。
- 辨識: 腳本讀取或寫入 Cookie,用來判斷這個使用者是誰、從哪裡來。
- 傳送: 腳本從瀏覽器發送請求,把瀏覽、點擊、加入購物車、購買等事件傳給 Meta、Google 或其他廣告平台。
這套追蹤方式過去很好用,因為它簡單、便宜,而且行銷人自己用 GTM 就能完成大部分設定。
但從上面的敘述應該不難發現,整套追蹤邏輯完全建構於使用者的「瀏覽器」之上。
只要瀏覽器不讓你寫 Cookie、使用者裝了 Ad block 或是網頁載入過程中腳本沒有成功執行,追蹤資料就可能遺失形成斷點,
這也是為什麼近十年來廣告成效會越來越難做的原因之一。因為廣告系統能辨識消費者的訊號變少了,演算法需要越來越複雜的用戶 pattern 去旁敲側擊地找出潛在客戶,甚至不惜用通靈的方式在廣告後台顯示高成效的快樂錶,而你實際透過廣告賺取地訂單金額根本沒有後台寫得這麼漂亮。
順帶一提,我知道很多人不習慣用 Safari,會在手機中安裝其他瀏覽器來瀏覽網頁,但只要你在 iOS 系統上點開任何的 In-App Browser,都會是使用和 Safari 一樣的 WebKit 架構,所以不管你在 facebook 或 LINE 之類的社群 App 點開網頁,都會受到蘋果 ITP 政策的保護。
通往魔多的另一條路
那難道沒有一種方式可以不受瀏覽器政策的限制,將真實的用戶資料傳給廣告商嗎?
有的,朋友,有的
雖然佛羅多沒辦法直接走正門大搖大擺的走進魔多,但其實還有一條蜿蜒的老路可以直通末日火山,這就是多數 affiliate 系統、DSP、CPA offer 長期在使用的 Server-to-Server Tracking,以下簡稱 S2S。

S2S 的核心概念其實不難:
不要讓瀏覽器負責回傳最重要的轉換資料,而是改由網站伺服器直接把轉換結果送回追蹤平台。
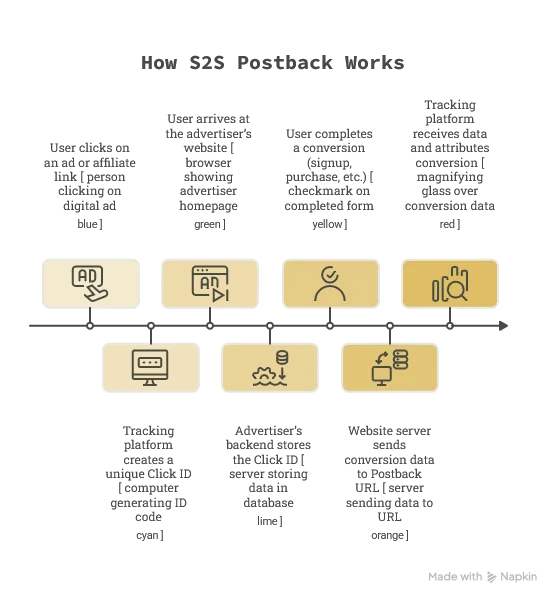
以 affiliate 常見的 S2S Postback 為例,流程大概是這樣:
點擊生成唯一識別碼: 當使用者點擊聯盟專屬連結時,聯盟平台會生成一個全球唯一的 Click ID(例如網址後方的
?click_id=abc123xyz)。廣告主伺服器記錄: 使用者進入廣告主網站後,廣告主的系統會把這組 Click ID 存起來。可能是存在資料庫、Session、第一方 Cookie,或跟使用者的會員資料、訂單流程綁在一起。
轉換發生時,由伺服器發送 Postback: 當使用者完成註冊、下單、付款或其他指定轉換事件時,廣告主的伺服器會直接發送一個 HTTP request 到追蹤平台的 Postback URL。將帶有該 Click ID 與訂單金額等必要資料,傳回給聯盟平台,完成一次轉換的紀錄。
我知道這幾段內容對沒有程式基礎的行銷人員來說可能會有點難理解,所以我再簡單的解釋一下。
傳統 Pixel 追蹤比較像是:
使用者在網站上做了某件事,然後他的瀏覽器幫你打電話通知廣告平台。
S2S 追蹤則比較像是:
使用者真的完成轉換後,由網站後台直接打電話通知廣告平台。
所以 S2S 的價值不是什麼神秘黑科技,而是它把最重要的轉換回傳,從容易被干擾的前端,移到相對穩定的後端。
這也是為什麼 affiliate 系統很早就大量使用 S2S Postback,因為這會直接影響到給 affiliate partner 的分潤金額,雙方都會特別重視資料的正確程度。
先釐清:S2S、CAPI、GTM Server-Side 不是完全同一件事
這裡要先補一個很重要的觀念。
現在很多人會把 Server-Side Tracking、S2S Postback、Meta CAPI、Google Enhanced Conversions、GTM Server-Side 全部混在一起講。
它們確實都跟「從伺服器端傳送資料」有關,但它們不是完全一樣的東西。
你可以先簡單這樣理解:
| 類型 | 主要用途 | 常見情境 |
|---|---|---|
| S2S Postback | 用 Click ID 回傳最終轉換 | Affiliate、DSP、CPA offer |
| Conversions API / Enhanced Conversions | 從網站後端把事件送給廣告平台 | Meta、Google、TikTok 廣告最佳化 |
| GTM Server-Side | 建立一個伺服器端資料中繼站,負責收集、清洗、分發事件 | 多平台追蹤、資料治理、事件去重 |
這篇文章會重點著墨於 S2S tracking 的基礎認識。至於 GTM Server-Side、雲端架構、資料清洗、事件去重、Hybrid Tracking 等更細的實作問題,會是後面更進階的主題。
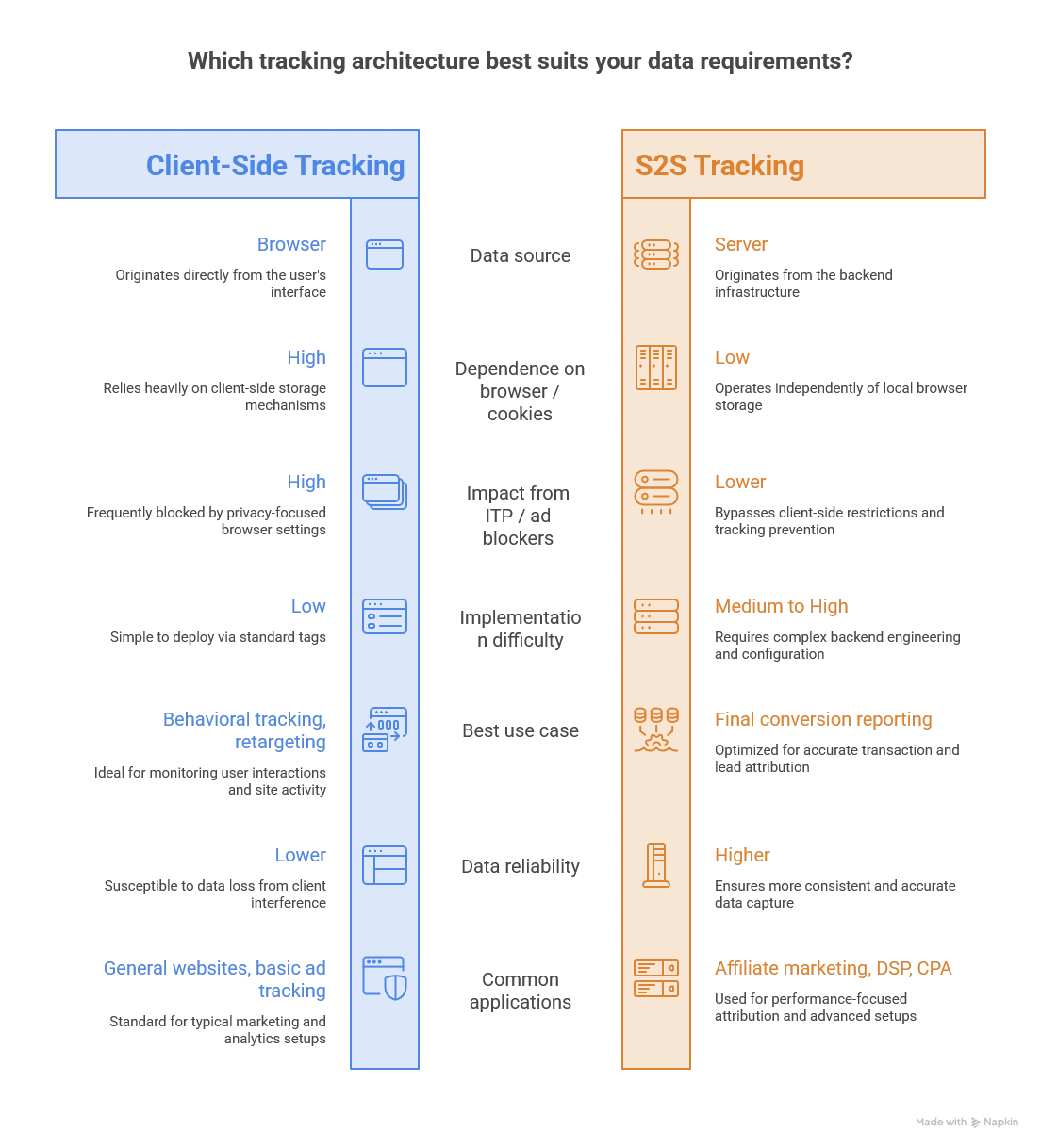
S2S 追蹤的短版
為什麼 S2S 追蹤資料這麼簡單高效,難道就沒有什麼缺點嗎?
當然還是有,雖然單純的 Postback 歸因極度精準,但它存在一個致命缺陷:只能處理單一的最終轉換結果(如購買、註冊)。當這個訪客完全沒有註冊會員或根本沒下訂單時,系統會連他來過你網站的資料都沒有。
這會造成兩個問題。
第一,你很難分析中間漏斗。
你只知道誰最後買了,卻不知道更多人是在哪一步離開。
第二,你很難做再行銷。
因為很多再行銷受眾,仍然需要前端事件、瀏覽行為、互動資料或廣告平台可以識別的訊號。
所以 S2S 不是萬靈丹。
它很適合補強最重要的轉換回傳,但不代表你可以把所有前端追蹤全部關掉。
真正成熟的做法:走向 Hybrid Tracking
Hybrid Tracking 的概念是:
前端負責收集瀏覽器環境、頁面互動、使用者行為等訊號;後端負責回傳更穩定、更可信的轉換資料。
簡單講,就是前後端分工。
前端仍然有價值,因為它能看到使用者在頁面上的行為,例如瀏覽頁面、點擊按鈕、加入購物車、停留時間、表單互動等等。
後端也有價值,因為它能確認真正發生的商業結果,例如付款完成、訂單成立、會員註冊、首儲成功。
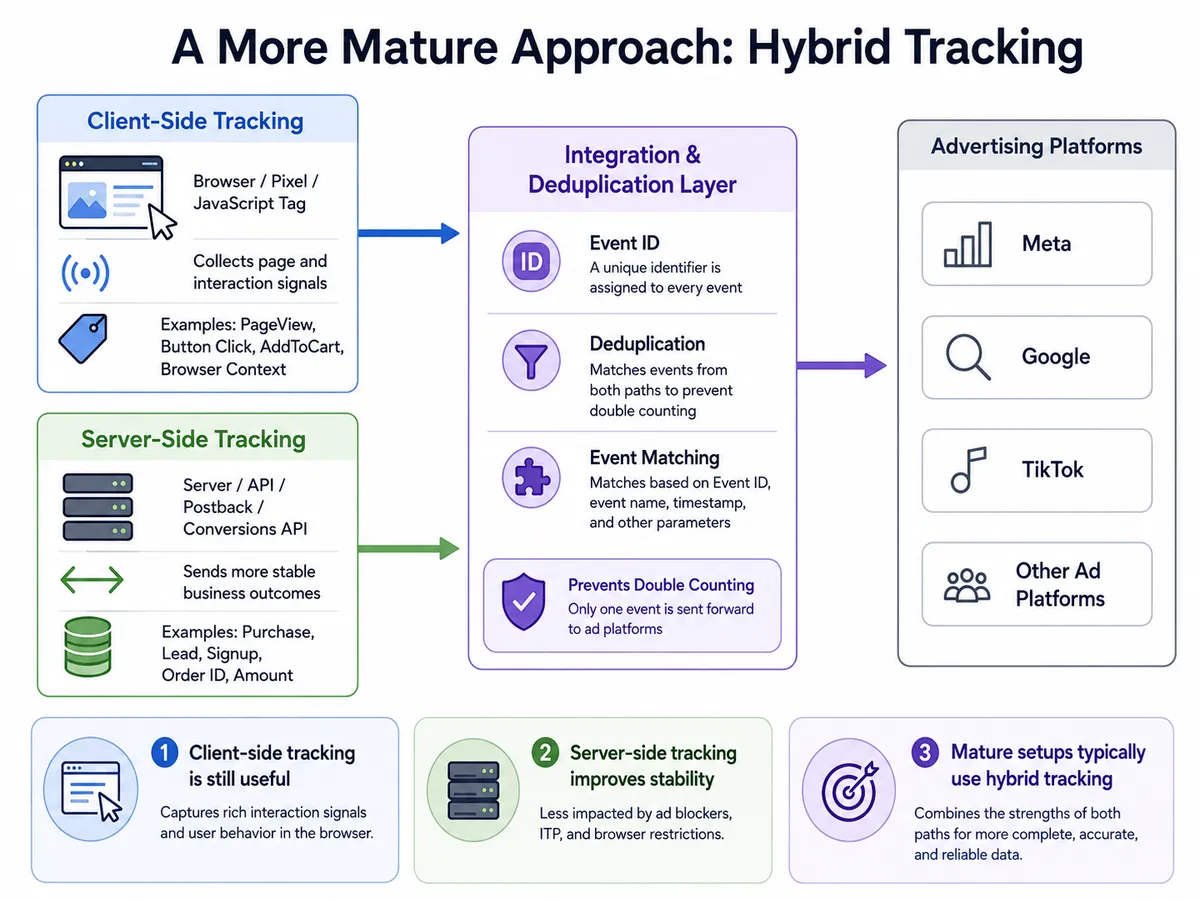
但 Hybrid Tracking 也會帶來新的問題:
同一個事件可能會被前端和後端各送一次。
例如一筆購買事件,如果前端 Pixel 送了一次,後端 CAPI 又送了一次,而平台沒有正確判斷這兩筆其實是同一個事件,就可能造成重複計算。
這時候就需要設計 Deduplication,事件去重機制。
也就是讓前端和後端送出的同一個事件,共用同一組 Event ID,讓廣告平台知道:
這兩筆資料講的是同一件事,不要算兩次。
這部分就是 Server-Side Tracking 真正容易出錯的地方。
因為你不是只要「把資料送出去」而已。
你還要確保資料沒有重複、沒有漏接、欄位格式正確,而且能被不同廣告平台正確理解。
這也是我認為行銷人需要懂基本追蹤架構的原因。你需要理解整套的運作邏輯與其中可能的坑,才不會花了大把的時間、精力甚至是金錢。卻反而造成反效果。
S2S 系統建置評估
將追蹤架構從純前端轉移至伺服器端,不是單純多裝一個外掛,也不是在 GTM 裡新增一個 Tag 就結束。這是一項涉及基礎設施的系統工程。在全面導入之前,至少要評估幾件事。
資料準確度
這是導入 S2S 最主要的原因,整個系統建置起來理論上可以找回 15%~30% 的訂單資料,但如果沒有設計好去重機制,可能會導致廣告平台接收到的資料被嚴重汙染,影響平台演算法的機器學習,所以務必要測試完整再發布上線。
網站讀取速度
這點比較像是意外收穫,由於前端的 JavaScript 腳本不會只有廣告追蹤的部分,很多 SAAS 系統如客服外掛系統、EDM 系統等等也有可能用前端的方式寫入,這些資料完全可以直接交由伺服器端來發送,用來減輕前端的載入壓力,提升 Core Web Vitals 與載入速度,你的 SEO 網頁評分與用戶體驗可能也會提高一些。
團隊溝通成本
這可能是很多公司最容易低估的地方。
有別於以往的追蹤部屬,行銷人員只需要自己操作 GTM 就能簡單的完成,S2S 會根本上的動到整個網站的資料傳輸結構,所以需要花點時間跟平常不會碰到行銷需求的 backend 開發人員解釋需求跟設計流程,行銷人員必須清楚這整套系統的運作架構,才有可能正確的建立與技術人員溝通的橋樑。
建置與維護成本
Server-Side Tracking 不是免費的。
即使你使用 GTM Server-Side,也可能需要雲端主機成本,例如 Google Cloud、Cloud Run、App Engine,或第三方 Server-Side GTM 服務。
這些可能都是以往沒有的額外的定期開銷。
結論:這不只是 IT 問題,而是建構面向未來的數據架構決策
在「隱私權至上」的後 Cookie 時代,Server-Side Tracking 雖然有建置門檻與主機成本,但它能幫你買回最寶貴的資產——真實的數據與準確的廣告歸因。當你比競爭對手更早把這條「地下專線」牽好,你的廣告機器學習就會比別人更聰明,這將是未來數位行銷戰場上的最大護城河。
它要求跨部門的深度協作:行銷人員必須定義出有價值的漏斗節點,廣告投手需要理解歸因邏輯的轉變,而系統工程師則必須確保資料流的嚴謹性與防呆機制。只有當三方建立起共同的技術語言,這套兼具精準度與隱私安全的數據架構,才能真正發揮其績效極大化的商業價值。